NullPointerException is one of the most common causes for failure of Java programs.
In the simplest cases the compiler can directly warn you when it sees code like this:
Object o = null;
String s = o.toString();
With branching / looping and throwing exceptions quite sophisticated flow analysis becomes necessary in order to figure out if a variable being dereferenced has been assigned a null / non-null value on some or all paths through the program.
Due to the inherent complexity, flow analysis is best performed in small chunks. Analyzing one method at a time can be done with good tool performance - whereas whole-system analysis is out of scope for the Eclipse Java compiler. The advantage is: analysis is fast and can be done incrementally such that the compiler can warn you directly as you type. The down-side: the analysis can not "see" which values (null or non-null) are flowing between methods (as parameters and return values).
This is where null annotations come into play.
By specifying a method parameter as @NonNull you can tell the compiler
that you don't want a null value in this position.
String capitalize(@NonNull String in) {
return in.toUpperCase(); // no null check required
}
void caller(String s) {
if (s != null)
System.out.println(capitalize(s)); // preceding null check is required
}
In the vein of Design-by-Contract this has two sides:
capitalize enjoys the
guarantee that the argument in shall not be null
and thus dereferencing without a null check is OK here.
For method return values the situation is symmetric:
@NonNull String getString(String maybeString) {
if (maybeString != null)
return maybeString; // the above null check is required
else
return "<n/a>";
}
void caller(String s) {
System.out.println(getString(s).toUpperCase()); // no null check required
}
The Eclipse Java compiler can be configured to use three distinct annotation types for its enhanced null analysis (which is disabled by default):
@NonNull: null is not a legal value@Nullable: null value is allowed and must be expected@NonNullByDefault: types in method signatures and field declarations
that lack a null annotation are regarded as non-null.Annotations @NonNull and @Nullable are supported in these locations:
@NonNullByDefault is supported for
package-info.java) - to affect all types in the package
Note, that even the actual qualified names of these annotations are
configurable,
but by default the ones given above are used (from the package org.eclipse.jdt.annotation).
When using 3rd party null annotation types, please ensure that those are properly defined using at least a @Target
meta annotation, because otherwise the compiler can not distinguish between declaration annotations (Java 5)
and type annotations (Java 8). Furthermore, some details of @NonNullByDefault are not supported when using
3rd party annotation types (see here for the Java 8 variant).
A JAR with the default null annotations is shipped with Eclipse in eclipse/plugins/org.eclipse.jdt.annotation_*.jar. This JAR needs to be on the build path at compile time but it is not necessary at run time (so you don't have to ship this to users of your compiled code).
Starting with Eclipse Luna, two versions of this jar exist, one with declaration annotations for use in Java 7 or below (version 1.1.x) and one with null type annotations for use in Java 8 (version 2.0.x).
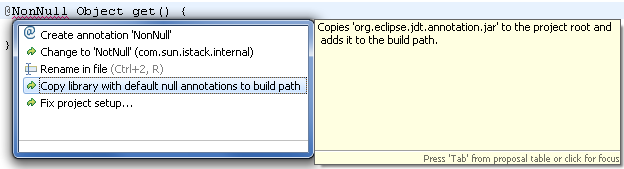
For plain Java projects there is also a quick fix on unresolved references to @NonNull, @Nullable, or @NonNullByDefault
that adds the suitable version of the JAR to the build path:
For OSGi bundles / plug-ins please add one of the following entries to your MANIFEST.MF:
Require-Bundle: ..., org.eclipse.jdt.annotation;bundle-version="[1.1.0,2.0.0)";resolution:=optional
Require-Bundle: ..., org.eclipse.jdt.annotation;bundle-version="[2.0.0,3.0.0)";resolution:=optional
See also the discussion in the corresponding section on compatibility.
It should be clear now that null annotations add more information to your Java program (which can then be used by the compiler to give better warnings). But what exactly do we want these annotations to say? From a pragmatic point of view there are at least three levels of what we might want to express with null annotations:
For (1) you may start using null annotations right away and without reading further, but you shouldn't expect more than a little hint every now and then. The other levels deserve some more explaining.
At first sight using null annotations for API specifications in the vein of Design by Contract
only means that the signatures of all API methods should be fully annotated,
i.e., except for primitive types like int each parameter and each
method return type should be marked as either @NonNull or @Nullable.
Since this would mean to insert very many null annotations, it is good to know that in
well-designed code (especially API methods), @NonNull is significantly more
frequent than @Nullable. Thus the number of annotations can be reduced by
declaring @NonNull as the default, using a @NonNullByDefault
annotation at the package level.
Note the significant difference between @Nullable and omitting a null annotation:
This annotation explicitly states that null is OK and must be expected.
By contrast, no annotation simply means, we don't know what's the intention.
This is the old situation where sometimes both sides (caller and callee) redundantly check for null,
and some times both sides wrongly assume that the other side will do the check.
This is where NullPointerExceptions originate from.
Without an annotation the compiler will not give specific advice, but with a
@Nullable annotation every unchecked dereference will be flagged.
With these basics we can directly map all parameter annotations to pre-conditions and interpret return annotations as post-conditions of the method.
In object-oriented programming the concept of Design by Contract needs to address one more dimension:
sub-typing and overriding (in the sequel the term "override" will be used in the sense of the
@Override annotation in Java 6: methods overriding or implementing another method
from a super-type). A client invoking a method like this one:
@NonNull String checkedString(@Nullable String in)
should be allowed to assume that all implementations of this method fulfill the contract.
So when the method declaration is found in an interface I1,
we must rule out that any class Cn implementing I1 provides
an incompatible implementation. Specifically, it is illegal if any Cn tries
to override this method with an implementation that declares the parameter as @NonNull.
If we would allow this, a client module programmed against I1 could legally
pass null as the argument but the implementation would assume a non-null value -
unchecked dereference inside the method implementation would be allowed but blow up at runtime.
Hence, a @Nullable parameter specification obliges all overrides
to admit null as an expected, legal value.
Conversely, a @NonNull return specification obliges all overrides
to ensure that null will never be returned.
Therefore, the compiler has to check that no override adds a @NonNull
parameter annotation (or a @Nullable return annotation) that didn't exist in the super-type.
Interestingly, the reverse redefinitions are legal: adding a @Nullable parameter annotation
or a @NonNull return annotation (you may consider these as "improvements" of the method,
it accepts more values and produces a more specific return value).
By forcing sub-classes to repeat null annotations in any overriding methods, the null contract of each method can be understood without searching the inheritance hierarchy. However, in situations where an inheritance hierarchy mixes code of different provenance it may not be possible to add null annotations to all classes at once. In these situations the compiler can be told to treat methods with missing null annotations as if annotations from an overridden method were inherited. This is enabled using the compiler option inherit null annotations. It is possible that a method overrides two methods with different null contracts. Also a nullness default can be applicable at a method which is in conflict with an inherited null annotation. These cases are flagged as an error and the overriding method must use an explicit null annotation to resolve the conflict.
@NonNull Parameter to Unspecified?
If inheritance of null annotations
is not enabled, one particular situation is safe from a type theory point of view,
but may still indicate a problem:
Given a super method that declares a parameter as @NonNull and an overriding method
that does not constrain the corresponding parameter (neither by an explicit null annotation, nor
by an applicable @NonNullByDefault).
This is safe because clients seeing the super-declaration will be forced to avoid null
whereas the the overriding implementation simply cannot leverage this guarantee due to the
lack of a specification in this specific method.
Still this may lead to misconceptions because it may be intended that the declaration in the super type should apply also to all overrides.
For this reasons the compiler provides an option '@NonNull' parameter not annotated in overriding method:
null should indeed be acceptable it is good practice to add a @Nullable annotation to
override the @NonNull from the super method.
The previous considerations add a difficulty when annotated code is written as a sub-type
of a "legacy" (i.e., un-annotated) type (which may be from a 3rd party library, thus cannot be changed).
If you read the last section very carefully you might have noticed that we cannot admit
that a "legacy" method is overridden by a method with a @NonNull parameter
(since clients using the super-type don't "see" the @NonNull obligation).
In this situation you will be forced to omit null annotations (plans exist to support adding annotations to libraries after-the-fact, but no promise can be made yet, if and when such a feature will be available).
The situation will get tricky, if a sub-type of a "legacy" type resides in a package for which
@NonNullByDefault has been specified. Now a type with an un-annotated super-type
would need to mark all parameters in overriding methods as @Nullable:
even omitting parameter annotations isn't allowed because that would be interpreted like a
@NonNull parameter, which is prohibited in that position.
That's why the Eclipse Java compiler supports cancellation
of a nullness default: by annotating a method or type with @NonNullByDefault(false)
an applicable default will be canceled for this element, and un-annotated parameters are again interpreted as
unspecified. Now, sub-typing is legal again without adding unwanted @Nullable
annotations:
class LegacyClass {
String enhance (String in) { // clients are not forced to pass nonnull.
return in.toUpperCase();
}
}
@NonNullByDefault
class MyClass extends LegacyClass {
// ... methods with @NonNull default ...
@Override
@NonNullByDefault(false)
String enhance(String in) { // would not be valid if @NonNullByDefault were effective here
return super.enhance(in);
}
}
Canceling a nullness default may not be possible when using annotation types other than
org.eclipse.jdt.annotation.NonNullByDefault supplied by Eclipse,
because other annotation types may not declare the boolean property that is used here.
Null annotations work best when applied in method signatures (local variables typically don't even need these, but may also leverage null annotations for bridging between annotated code and "legacy" code). In such usage null annotations connect the chunks of intra procedural analysis as to achieve statements about global data flows. Starting with Eclipse Kepler null annotations can also be applied to fields, but here the situation is slightly different.
Consider a field marked with @NonNull: this obviously requires that any
assignment to the field provides a value that is known not to be null.
Additionally, the compiler must be able to verify that a non-null field can never be accessed
in its uninitialized state (in which it still has the value null).
If it can be verified that every constructor complies to this rule (similarly a static
field must have an initializer), the program benefits from the safety that dereferencing
the field can never cause a NullPointerException.
The situation is more delicate when considering a field marked @Nullable.
Such a field should always be considered as dangerous and the recommended way of working
with nullable fields is: always assign the value to a local variable before working with it.
Using a local variable the flow analysis can tell exactly, whether a dereference is
sufficiently protected by a null check. When following this general rule working with nullable
fields poses no problems.
Things get more involved when the code directly dereferences the value of a nullable field. The problem is that any null checks that the code may perform before the dereference can easily be invalidated by one of these:
One can easily see that without also analyzing thread synchronization (which is beyond the compiler's capabilities) no null-check against a nullable field will ever grant 100% safety for a subsequent dereference. So if concurrent access to a nullable field is possible, the field's value should never be directly dereferenced, always a local variable should be used instead. Even if no concurrency is involved, the remaining issues pose a challenge to a complete analysis that is harder than what a compiler can typically handle.
Given the compiler cannot fully analyze the effects of aliasing, side effects and concurrency, the Eclipse compiler does not perform any flow analysis for fields (other than regarding their initialization). Since many developers will consider this limitation as too restrictive - requiring the use of local variables where developers feel that their code should actually be safe - a new option has been introduced as a tentative compromise:
The compiler can be configured to perform some syntactic analysis. This will detect the most obvious patterns like this:
@Nullable Object f;
void printChecked() {
if (this.f != null)
System.out.println(this.f.toString());
}
With the given option enabled the above code will not be flagged by the compiler. It is important to see that this syntactic analysis is not "smart" in any way. If any code appears between the check and the dereference the compiler will cowardly "forget" the information of the previous null check, without even trying to see if the intermediate code could perhaps be harmless according to some criteria. Thus please be advised: whenever the compiler flags a dereference of a nullable field as unsafe although the human eye may see that null should not occur, please either rewrite your code to closely follow the recognized pattern shown above, or, even better: use a local variable to leverage all the sophistication of flow analysis, which syntactic analysis will never attain.
Using null annotations in the style of Design-by-Contract as outlined above, helps to improve the quality of your Java code in several ways: At the interface between methods it is made explicit, which parameters / returns tolerate a null value and which ones don't. This captures design decisions, which are highly relevant to the developers, in a way that is also checkable by the compiler.
Additionally, based on this interface specification the intra-procedural flow analysis can pick up available information and give much more precise errors/warnings. Without annotations any value flowing into or out of a method has unknown nullness and therefore null analysis remains silent about their usage. With API-level null annotations the nullness of most values is actually known, and significantly fewer NPEs will go unnoticed by the compiler. However, you should be aware that still some loopholes exist, where unspecified values flow into the analysis, preventing a complete statement whether NPEs can occur at runtime.
The support for null annotations had been designed in a way that should be compatible to a future extension. This extension has become part of the Java language as type annotations (JSR 308), which have been introduced in Java 8. JDT supports to leverage the new concept for null type annotations.
Semantic details of annotation based null analysis are presented here, by explaining the rules that the compiler checks and the messages it issues upon violation of a rule.
On the corresponding preference page the individual rules checked by the compiler are grouped under the following headings:
As specification violation we handle any situation where a null annotation
makes a claim that is violated by the actual implementation. The typical situation results
from specifying a value (local, argument, method return) as @NonNull whereas
the implementation actually provides a nullable value. Here an expression is considered as
nullable if either it is statically known to evaluate to the value null, or if it is declared
with a @Nullable annotation.
Secondly, this group also contains the rules for method overriding as discussed
above.
Here a super method establishes a claim (e.g., that null is a legal argument)
while an override tries to evade this claim (by assuming that null is not a legal argument).
As mentioned even specializing an argument from un-annotated to @NonNull
is a specification violation, because it introduces a contract that should bind the client
(to not pass null), but a client using the super-type won't even see this contract,
so he doesn't even know what is expected of him.
The full list of situations regarded as specification violations is given
here.
It is important to understand that errors in this group should never be ignored,
because otherwise the entire null analysis will be performed based on false assumptions.
Specifically, whenever the compiler sees a value with a @NonNull annotation
it takes it for granted that null will not occur at runtime.
It's the rules about specification violations which ensure that this reasoning is sound.
Therefore it is strongly recommended to leave this kind of problem configured as errors.
Also this group of rules watches over the adherence to null specifications.
However, here we deal with values that are not declared as @Nullable
(nor the value null itself), but values where the intra-procedural flow analysis
infers that null can possibly occur on some execution path.
This situation arises from the fact that for un-annotated local variables the compiler will infer whether null is possible using its flow analysis. Assuming that this analysis is accurate, if it sees a problem this problem has the same severity as direct violations of a null specification. Therefore, it is again strongly recommended to leave these problems configured as errors and not to ignore these messages.
Creating a separate group for these problems serves two purposes: to document that a given problem was raised with the help of the flow analysis, and: to account for the fact that this flow analysis could be at fault (because of a bug in the implementation). For the case of an acknowledged implementation bug it could in exceptional situations be OK to suppress an error message of this kind.
Given the nature of any static analysis, the flow analysis may fail to see that a certain combination of execution paths and values is not possible. As an example consider variable correlation:
String flatten(String[] inputs1, String[] inputs2) {
StringBuffer sb1 = null, sb2 = null;
int len = Math.min(inputs1.length, inputs2.length);
for (int i=0; i<len; i++) {
if (sb1 == null) {
sb1 = new StringBuffer();
sb2 = new StringBuffer();
}
sb1.append(inputs1[i]);
sb2.append(inputs2[i]); // warning here
}
if (sb1 != null) return sb1.append(sb2).toString();
return "";
}
The compiler will report a potential null pointer access at the invocation of sb2.append(..).
The human reader can see that there is no actual danger because sb1 and sb2
actually correlate in a way that either both variables are null or both are not null.
At the line in question we know that sb1 is not null, hence also sb2
is not null. Without going into the details why such correlation analysis is beyond the capability
of the Eclipse Java compiler, please just keep in mind that this analysis doesn't have the power of a
full theorem prover and therefore pessimistically reports some problems which a more capable
analysis could possibly identify as false alarms.
If you want to benefit from flow analysis, you are advised to give a little help to the compiler
so it can "see" your conclusions. This help can be as simple as splitting the if (sb1 == null)
into two separate ifs, one for each local variable, which is a very small price to pay for the
gain that now the compiler can exactly see what happens and check your code accordingly.
More discussion on this topic will follow below.
This group of problems is based on the following analogy: in a program using Java 5 generics any calls to pre-Java-5 libraries may expose raw types, i.e., applications of a generic type which fail to specify concrete type arguments. To fit such values into a program using generics the compiler can add an implicit conversion by assuming that type arguments were specified in the way expected by the client part of the code. The compiler will issue a warning about the use of such a conversion and proceed its type checking assuming the library "does the right thing". In exactly the same way, an un-annotated return type of a library method can be considered as a "raw" or "legacy" type. Again an implicit conversion can optimistically assume the expected specification. Again a warning is issued and analysis continues assuming that the library "does the right thing".
Theoretically speaking, also the need for such implicit conversions indicates a specification violation. However, in this case it may be 3rd party code that violates the specification which our code expects. Or, maybe (as we have convinced ourselves of) some 3rd party code does fulfill the contract, but only fails to declare so (because it doesn't use null annotations). In such situations we may not be able to exactly fix the problem for organizational reasons.
@SuppressWarnings("null")
@NonNull Foo foo = Library.getFoo(); // implicit conversion
foo.bar();
The above code snippet assumes that Library.getFoo() returns a Foo
without specifying a null annotation. We can integrate the return value into our annotated
program by assignment to a @NonNull local variable, which triggers a warning
regarding an unchecked conversion.
By adding a corresponding SuppressWarnings("null") to this declaration
we acknowledge the inherent danger and accept the responsibility of having verified that
the library actually behaves as desired.
If flow analysis cannot see that a value is indeed not null, the simplest strategy is always
to add a new scoped local variable annotated with @NonNull.
Then, if you are convinced that the value assigned to this local will never be null at runtime you can use a helper methods like this:
static @NonNull <T> T assertNonNull(@Nullable T value, @Nullable String msg) {
if (value == null) throw new AssertionError(msg);
return value;
}
@NonNull MyType foo() {
if (isInitialized()) {
MyType couldBeNull = getObjectOrNull();
@NonNull MyType theValue = assertNonNull(couldBeNull,
"value should not be null because application " +
"is fully initialized at this point.");
return theValue;
}
return new MyTypeImpl();
}
Note that by using the above assertNonNull() method you are accepting the responsibility
that this assertion will always hold at runtime.
If that is not what you want, annotated local variables will still help to narrow down where and why the analysis
sees a potential for null flowing into a certain location.
At the time of releasing the JDT version 3.8.0, collecting advice for adopting null annotations is still work in progress. For that reason this information is currently maintained in the Eclipse wiki.