
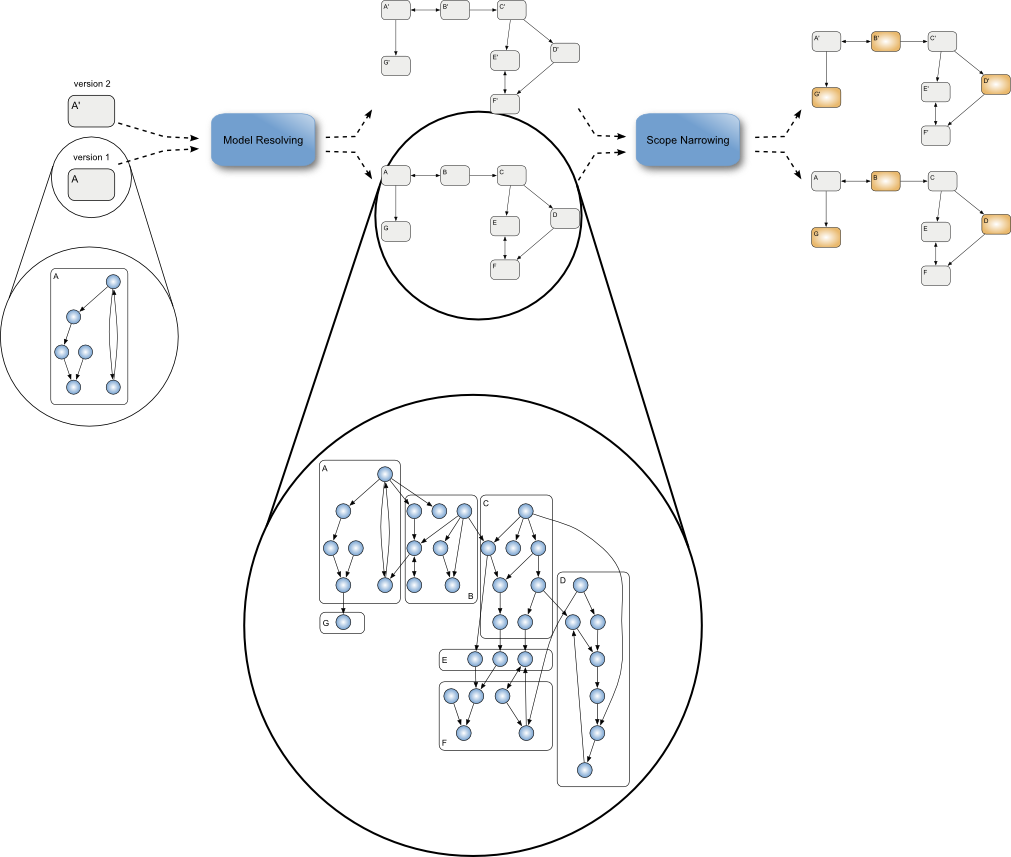
The above figure represents the comparison process of EMF Compare. It can be roughly divided in 6 main phases.
From a given "starting point" (the file a user decided to compare), finding all other fragments required for the comparison of the whole logical model.
Iterating over the two (or three) loaded logical models in order to map elements together two-by-two (or three-by-three). For example, determine that class Class1 from the first model corresponds to class Class1' from the second model.
The matching phase told us which elements were matching together. The differencing phase will browse through these mappings and determine whether the two (or three) elements are equal or if they present differences (for example, the name of the class changed from Class1 to Class1').
The differencing phases detected a number of differences between the compared models. However, two distinct differences might actually represent the same change. This phase will browse through all differences and link them together when they can be seen as equivalent (for example, differences on opposite references).
For the purpose of merging differences, there might be dependencies between them. For example, the addition of a class C1 in package P1 depends on the addition of package P1 itself. During this phase, we'll browse through all detected differences and link them together when we determine that one cannot be merged without the other.
When we're comparing our file with one from EGit, there might actually be conflicts between the changes we've made locally, and the changes that were made to the file on the remote repository. This phase will browse through all detected differences and detect these conflicts. It could also happen on three-way comparisons.
The Model resolving phase itself can be further decomposed in its own two distinct phases. More on the logical model and its resolution can be found on the dedicated page.
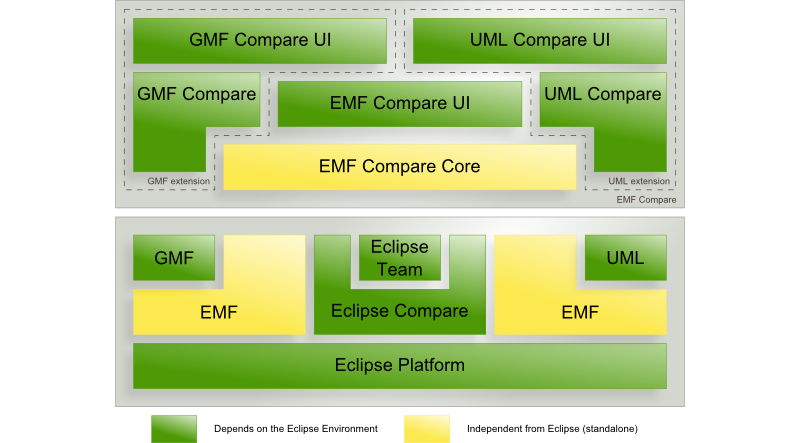
EMF Compare is built on top of the Eclipse platform. We depend on the Eclipse Modeling Framework (EMF), the Eclipse Compare framework and, finally, Eclipse Team, the framework upon which the repository providers (EGit, CVS, Subversive...) are built.
The EMF Compare extensions target specific extensions of the modeling framework: UML, the Graphical Modeling Framework (and its own extensions, ecoretools, ...).
Whilst we are built atop bricks that are tightly coupled with the eclipse platform, it should be noted that the core of EMF Compare can be run in a standalone application with no runtime dependencies towards Eclipse; as can EMF itself.
EMF Compare uses a single model, whose root is a Comparison object, to represent all of the information regarding the comparison: matched objects, matched resources, detected differences, links between these references, etc. The root Comparison is created at the beginning of the Match process, and will undergo a set of successive refinements during the remainder of the Comparison: Diff, Equivalence, Dependencies... will all add their own information to the Comparison.
Here is an overview of the EMF Compare metamodel:
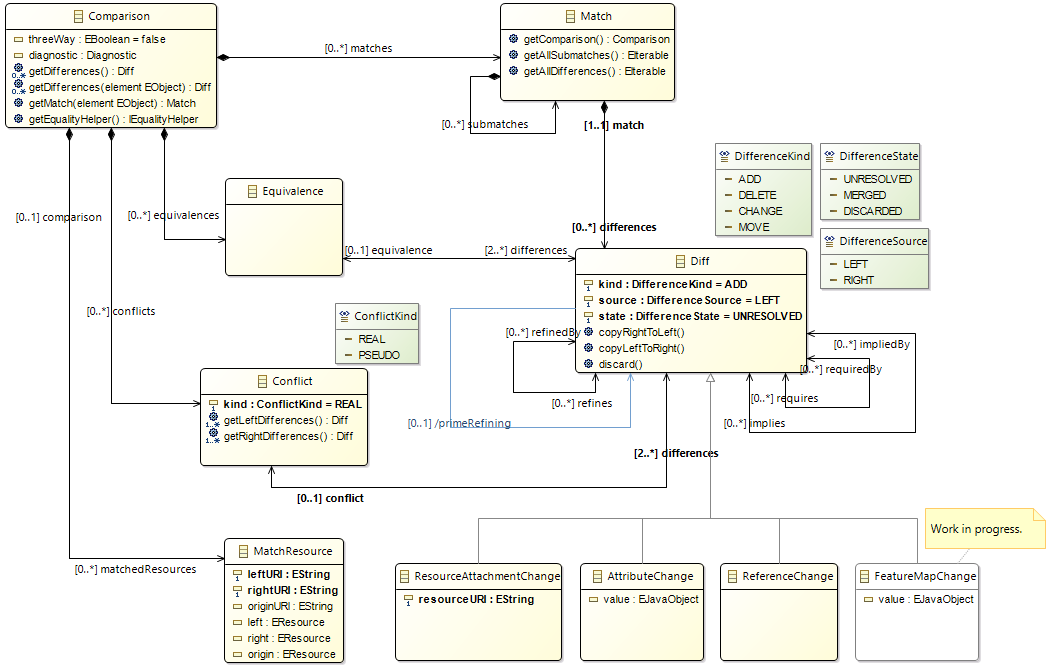
So, how exactly is all of the information the Comparison model can hold represented, and how to make sense of it all?
A Match element is how we represent that the n compared versions have elements that are basically the same. For example, if we are comparing two different versions v1 and v2 of a given model which look like:
| Master | Borrowables |
|---|---|
|
|
Comparing these two models, we'll have a Comparison model containing three matches:
In other words, the comparison model contains an aggregate of the two or three compared models, in the form of Match elements linking the elements of all versions together. Differences will then be detected on these Match and added under them, thus allowing us to know both:
Diff elements are created during the differencing process in order to represent the actual modifications that can be detected within the source model(s). The Diff concept itself is only there as the super-class of the three main kind of differences EMF Compare can detect in a model, namely ReferenceChange, AttributeChange and ResourceAttachmentChange. We'll go back to these three sub-classes in a short while.
Whatever their type, the differences share a number of common elements:
In order to ensure that the model remains consistent through individual merge operations, we've also decided to link differences together through a number of associations and references. For example, there are times when one difference cannot be merged without first merging another, or some differences which are exactly equivalent to one another. In no specific order:
As mentioned above, there are only three kind of differences that we will detect through EMF Compare, which will be sufficient for all use cases. ReferenceChange differences will be detected for every value of a reference for which we detect a change. Either the value was added, deleted, or moved (within the reference or between distinct references). AttributeChange differences are the same, but for attributes instead of references. Lastly, the ResourceAttachmentChange differences, though very much alike the ReferenceChanges we create for containment references, are specifically aimed at describing changes within the roots of one of the compared resources.
Conflict will only be detected during three-way comparisons. There can only be "conflicts" when we are comparing two different versions of a same model along with their common ancestor. In other words, we need to able to compare two versions of a common element with a "reference" version of that element.
There are many different kinds of conflicts; to name a few:
Conflicts can be of two kinds. We call PSEUDO conflict a conflict where the two sides of a comparison have changed as compared to their common ancestor, but where the two sides are actually now equal. In other words, the end result is that the left is now equal to the right, even though they are both different from their ancestor. This is the opposite of REAL conflict where the value on all three sides is different. In terms of merging, pseudo conflicts do not need any particular action, whilst real conflicts actually need resolution.
There can be more than two differences conflicting with each other. For example, the deletion of an element from one side will most likely conflict with a number of differences from the other side.
EMF Compare uses Equivalence elements in order to link together a number of differences which can ultimately be considered to be the same. For example, ecore's eOpposite references will be maintained in sync with one another. As such, modifying one of the two references will automatically update the second one accordingly. The manual modification and the automatic update are two distinct modifications of the model, resulting in two differences detected. However, merging any of these two differences will automatically merge the other one. Therefore both are marked as being equivalent to each other.
There can be more than two differences equivalent with each other; in which case all will be added to a single Equivalence object, representing their relations.
When cross-referencing objects from another resource, EMF may use proxies instead of the actual object. As long as you do not access the element in question, EMF does not need to load the resource in which it is contained. The proxy is kind of a placeholder that tells EMF what resource should be loaded, and which of this resource's objects is referenced, when we actually need to access its value.
Proxy resolution is generally transparent, but a lot of tools based on EMF do not consider these proxies as first-class citizens: they simply resolve them without considering that they might not be needed. On the other hand, EMF Compare will never resolve proxies except for those strictly necessary. Whatever the phase of comparison, we strive to never hold the whole model in memory.
The initial resolution phase is the most intensive in terms of proxy resolution and I/O operations. Though we will never hold the whole logical model in memory at any given time, we do resolve all cross-references of the compared resources, on all sides of the comparison. Since the logical model may be located in a lot of different files on disk, it might also be very heavy in memory if loaded entirely. However, even if EMF Compare does resolve all fragments composing that logical model, it also unloads them as soon as the cross-references are registered. In other words, what we create is a dependency graph between the resources, not a loaded model. Afterwards, we only reload in memory those resources that have actually changed, and can thus contain differences. There will be proxies between these "changed" resources and the unchanged ones we have decided not to reload, but EMF Compare will never resolve these proxies again (and, in fact, will prevent other tools from resolving them).
Note: At the time of writing, the user interface will never resolve any proxies either. This might change in the future for a better user experience since proxies usually end up displayed in strange manners.
The equality helper is a very central concept of EMF Compare. Of course, EMF Compare's aim is to be able to compare objects together, objects whose comparison is not trivial and cannot be done through a mere "equal or not" concept. However, we still need to be able to compare these objects at all time and, whenever possible, without a full-fledged comparison.
The equality helper will be used in all phases of the comparison, from matching to merging (please see the comparison process for a bird's eye view of the different comparison phases, or their detailed descriptions down below). The matching phase is precisely the time when EMF Compare is trying to match the elements from one side to the elements from the other side, by pairs. As such, we do not have -yet- the knowledge of which element matches with which other. However, for all subsequent phases, the equality helper will rely on information from the comparison itself (the Match elements) to make a fail-fast test for element 'equality'.
When we do not have this information, the equality helper will resort to less optimal algorithms. For any object that is not an EMF EObject, we will use strict equality through == and Object#equals() calls. One of the cause for EMF Compare failing to match attribute values together is in fact the lack of implementation of the equals method on custom datatypes (see the FAQ for more on that particular issue).
Note: The equality helper is used extensively, and any performance hit or improvement here will make a huge difference on the whole comparison process. Likewise, any mistake in a custom equality helper will introduce a lot of bugs.
As seen above, EMF Compare considers proxies as first-class citizens of the EMF realm. This mainly shows in the matching mechanism. EMF Compare uses a scoping mechanism to determine which elements should be matched together, and which others should be ignored. Any element that is outside of the comparison scope will be ignored by the comparison engine and left alone (if it is a proxy, it won't even be loaded). This also means that we won't really have a way to compare these proxy (or otherwise out-of-scope values) when the Diff process encounters them.
For example, an element that is outside of the comparison scope, but referenced by another element which is in the scope will need specific comparison means: we've ignored it during the matching phase, so we don't know which 'out-of-scope' element corresponds to which 'other out-of-scope' element. Consider the following: in the first model, a package P1 contains another package P2. In the right, a package P1' contains a package P2' ''. We've told EMF Compare that ''P2 and P2' are out of the comparison scope. Now how do we determine that the reference from P1 to P2 has changed (or, in this example, that it did not change)?
This is a special case that is handled by the IEqualityHelper. Specifically, when such cases are encountered, EMF Compare falls back to using the URI of the two objects to check for equality. This behavior can be changed by customizing the IEqualityHelper (see above).
By default, the only thing that EMF Compare considers "out of scope" are Ecore's "EGenericType" elements. These are usually meaningless as far as comparison is concerned (as they are located in derived references and will be merged along with their "true" difference anyway). Please take note that, when used from the user interface, EMF Compare will narrow down the scope even further through the resolution of the logical model and determining which resources are actually candidates for differences.
The comparison scope provides EMF Compare with information on the content of ResourceSets, Resources or EObjects, according to the entry point of the comparison. Take note that the scope is only used during the matching phase. The differencing phase only uses the result of the matching phase to proceed.
PENDING description of the algorithm, why do we use it, references
All main components of EMF Compare have been designed for extensibility. Some are only extensible when comparing models through your own actions, some can be customized globally for a given kind of model or metamodel... We'll outline the customization options of all 6 comparison phases in this section. (Any dead link? Report them on the forum!)
To adequately handle the comparison and merging of models that span across several resources (files), EMF Compare has to determine all dependencies among model resources in order to avoid breaking cross-references among model resources during a merge. It is not enough to only follow outgoing cross-references from model resources. Instead, EMF Compare needs to resolve outgoing and incoming cross-references to and from other model resources. Therefore, EMF Compare traverses through all model files within a configurable scope (container, project or the whole workspace in the EMF Compare preferences) before the comparison and merging, and tracks the dependencies among the visited model resources. The dependencies are stored and cached in terms of a graph, whereas nodes are model resources and edges are dependencies to other model resources. Based on this dependency graph, EMF Compare determines the set of model resources that must be included in a subsequent model comparison or merge.
The default implementation of the model resolution is multi-threaded and can be found in the class org.eclipse.emf.compare.ide.ui.internal.logical.resolver.ThreadedModelResolver.
The default implementation of the model resolution described above can be replaced completely with a custom implementation of a model resolver or it can be extended by registering custom dependency providers.
The "modelResolvers" extension point in the "org.eclipse.emf.compare.ide.ui" plug-in allows to register custom model resolvers. These model resolvers replace the default implementation (ThreadedModelResolver) and can therefore implement their own strategy.
Note: This extension point is currently in beta and may be removed in the future since the ThreadedModelResolver seems flexible enough to support all common usecases.
The custom model resolver must implement the IModelResolver interface ( org.eclipse.emf.compare.ide.ui.logical.IModelResolver) or extend the AbstractModelResolver ( org.eclipse.emf.compare.ide.ui.logical.AbstractModelResolver).
Warning: Replacing the default ThreadedModelResolver is NOT recommended since the logic to be implemented is very complex. Make sure there is no alternative way to reach your goal!
The "modelDependencyProvider" extension point in the "org.eclipse.emf.compare.ide.ui" plugin allows to extend the default model resolution mechanism. It allows to add additional custom dependencies for model resources that are not manifested in actual cross-references otherwise.
Note: This extension point is currently in beta and may change in the future.
The registered model dependency providers must implement the IDependencyProvider interface ( org.eclipse.emf.compare.ide.ui.dependency.IDependencyProvider).
The dependencies determined via the dependency providers are used in two ways in the default model resolver:
This functionality can be used to express dependencies among model resources that exist "by design" but are not physically manifested in the model resources (as resolvable proxies). For example, this extension point is used by Papyrus to express a dependency between .di, .uml, and .notation files even if these model resources are not actually referencing each other.
Before we can compute differences between two versions of a same Object, we must determine which are actually the "same" Object. For example, let's consider that my first model contains a Package P1 which itself contains a class C1; and that my second model contains a package P1 which contains a class C1. It may seem obvious for a human reader that "P1" and "C1" are the same object in both models. However, since their features might have changed in-between the two versions (for example, the "C1" might now be abstract, or it could have been converted to an Interface), this "equality" is not that obvious for a computer.
The goal of the "Match" phase is to discover which of the objects from model 2 match with which objects of model 1. In other words, this is when we'll say that two objects are one and the same, and that any difference between the two sides of this couple is actually a difference that should be reported as such to the user.
By default, EMF Compare browses through elements that are within the scope, and matches them through their identifier if they have one, or through a distance mechanism for all elements that have none. If the scope contains resources, EMF Compare will first match those two-by-two before browsing through all of their contained objects.
EMF Compare "finds" the identifier of a given object through a basic function that can be found in IdentifierEObjectMatcher.DefaultIDFunction. In short, if the object is a proxy, its identifier is its URI fragment. Otherwise its XMI ID (the identifier it was given in the XMI file) takes precedence over its functional ID (in ecore, an attribute that serves as an identifier). If the object is not a proxy and has neither XMI nor functional identifier, then the default behavior will simply pass that object over to the proximity algorithms so that it can be matched through its distance with other objects.
PENDING: brief description of the proximity algorithm
This behavior can be customized in a number of ways.
The most powerful (albeit most cumbersome) customization you can implement is to override the match engine EMF Compare uses. To this end you can either implement the whole contract, [ https://github.com/eclipse-emf-compare/emf-compare/blob/master/plugins/org.eclipse.emf.compare/src/org/eclipse/emf/compare/match/IMatchEngine.java IMatchEngine], in which case you will have to carefully follow the javadoc's recommendations, or extend the default implementation, [ https://github.com/eclipse-emf-compare/emf-compare/blob/master/plugins/org.eclipse.emf.compare/src/org/eclipse/emf/compare/match/DefaultMatchEngine.java DefaultMatchEngine].
A custom match engine can be used for your model comparison needs:
// for standalone usage
IMatchEngine.Factory.Registry registry = MatchEngineFactoryRegistryImpl.createStandaloneInstance();
// for OSGi (IDE, RCP) usage
// IMatchEngine.Factory.Registry registry = EMFCompareRCPPlugin.getDefault().getMatchEngineFactoryRegistry();
final IMatchEngine customMatchEngine = new MyMatchEngine(...);
IMatchEngine.Factory engineFactory = new MatchEngineFactoryImpl() {
public IMatchEngine getMatchEngine() {
return customMatchEngine;
}
};
engineFactory.setRanking(20); // default engine ranking is 10, must be higher to override.
registry.add(engineFactory);
EMFCompare.builder().setMatchEngineFactoryRegistry(registry).build().compare(scope);
By default, the logic EMF Compare uses to match resources together is very simple: if two resources have the same name (strict equality on the name, without considering folders), they match. When this is not sufficient, EMF Compare will look at the XMI ID of the resources' root(s). If the two resources share at least one root with an equal XMI ID, they match.
This can be changed by just implementing your own subclass of the DefaultMatchEngine and overriding its resource matcher. The method of interest here is DefaultMatchEngine#createResourceMatcher().
In some cases, there might be ways to identify your objects via "identifiers" that cannot be recognized as such by the default mechanism. For example, you might want each of your objects to be matched through their name alone, or through the composition of their name and their type... This can be achieved through code by simply redefining the function used by EMF Compare to find the ID of an object. The following code will tell EMF Compare that the identifier of all "MyEObject" elements is their name, and that any other element should go through the default behavior.
Function<EObject, String> idFunction = new Function<EObject, String>() {
public String apply(EObject input) {
if (input instanceof MyEObject) {
return ((MyEObject)input).getName();
}
// a null return here tells the match engine to fall back to the other matchers
return null;
}
};
// Using this matcher as fall back, EMF Compare will still search for XMI IDs on EObjects
// for which we had no custom id function.
IEObjectMatcher fallBackMatcher = DefaultMatchEngine.createDefaultEObjectMatcher(UseIdentifiers.WHEN_AVAILABLE);
IEObjectMatcher customIDMatcher = new IdentifierEObjectMatcher(fallBackMatcher, idFunction);
IComparisonFactory comparisonFactory = new DefaultComparisonFactory(new DefaultEqualityHelperFactory());
IMatchEngine.Factory.Registry registry = MatchEngineFactoryRegistryImpl.createStandaloneInstance();
// for OSGi (IDE, RCP) usage
// IMatchEngine.Factory.Registry registry = EMFCompareRCPPlugin.getDefault().getMatchEngineFactoryRegistry();
final MatchEngineFactoryImpl matchEngineFactory = new MatchEngineFactoryImpl(customIDMatcher, comparisonFactory);
matchEngineFactory.setRanking(20); // default engine ranking is 10, must be higher to override.
registry.add(matchEngineFactory);
Comparison result = EMFCompare.builder().setMatchEngineFactoryRegistry(registry).build().compare(scope);
There are some cases where you do not want the identifiers of your elements to be taken into account when matching the objects. This can easily be done when computing comparisons programmatically:
Through code
IMatchEngine.Factory.Registry registry === MatchEngineFactoryRegistryImpl.createStandaloneInstance(); // for OSGi (IDE, RCP) usage // IMatchEngine.Factory.Registry registry === EMFCompareRCPPlugin.getDefault().getMatchEngineFactoryRegistry(); final MatchEngineFactoryImpl matchEngineFactory = new MatchEngineFactoryImpl(UseIdentifiers.NEVER); matchEngineFactory.setRanking(20); // default engine ranking is 10, must be higher to override. registry.add(matchEngineFactory); Comparison result = EMFCompare.builder().setMatchEngineFactoryRegistry(registry).build().compare(scope);
From the user interface
PENDING: preference page
If you are happy with most of what the default behavior does, but would like to refine some of it, you can do so by post-processing the result of the match phase. The original models are only used when matching, and will never be queried again afterwards. All the remaining phases are incremental refinements of the "Comparison" model that's been created by the matching phase.
As such, you can impact all of the differencing process through this. Within this post-processing implementation, you can:
Defining a custom post-processor requires you to implement IPostProcessor and registering this sub-class against EMF Compare. The latter can be done via either an extension point, in which case it will be considered for all comparisons on models that match its enablement, or programmatically if you only want it active for your own actions:
Through code
The following registers a post-processor for all UML models. This post-processor will not be triggered if there are no UML models (matching the given namespace URI) within the compared scope.
IPostProcessor customPostProcessor = new CustomPostProcessor();
IPostProcessor.Descriptor descriptor = new BasicPostProcessorDescriptorImpl(customPostProcessor, Pattern.compile("http://www.eclipse.org/uml2/\\d\\.0\\.0/UML"), null);
PostProcessor.Registry registry = new PostProcessorDescriptorRegistryImpl();
registry.put(CustomPostProcessor.class.getName(), descriptor);
Comparison comparison = EMFCompare.builder().setPostProcessorRegistry(registry).build().compare(scope);
Through extension point
This accomplishes the exact same task, but it registers the post-processor globally. Any comparison through EMF Compare on a scope that contains models matching the given namespace URI will trigger that post-processor.
<extension point="org.eclipse.emf.compare.rcp.postProcessor">
<postProcessor class="my.package.CustomPostProcessor">
<nsURI value="http://www.eclipse.org/uml2/\\d\\.0\\.0/UML">
</nsURI>
</postProcessor>
Now that the Matching phase has completed and that we know how our objects are coupled together, EMF Compare no longer requires the two (or three) input models. It will no longer iterate over them or the comparison's input scope. From this point onward, only the result of our comparison, the Comparison object, will be refined through the successive remaining phases, starting with the Diff.
The goal of this phase is to iterate over all of our Match elements, be they unmatched (only one side has this object), couples (two of the three sides contain this object) or trios (all three sides have this object) and compute any difference that may appear between the sides. For example, an object that is only on one side of the comparison is an object that has been added, or deleted. But a couple might also represent a deletion: during three way comparisons, if we have an object in the common ancestor (origin) and in the left side, but not in the right side, then it has been deleted from the right version. However, this latter example might also be a conflict: we have determined that the object has been removed from the right side... but there might also be differences between the original version and the "left" version.
The differencing phase does not care about conflicts though: all it does is refine the comparison to tell that this particular Match has n diffs: one DELETE difference on the right side, and n differences on the left. Detecting conflicts between these differences will come at a later time, during the conflict resolution phase.
Customizations of this phase usually aim at ignoring specific differences.
As is the case for the Match phase, the most powerful customization you can implement for the differencing process is to override the diff engine EMF Compare uses. To this end you can either implement the whole contract, [ https://github.com/eclipse-emf-compare/emf-compare/blob/master/plugins/org.eclipse.emf.compare/src/org/eclipse/emf/compare/diff/IDiffEngine.java IDiffEngine], in which case you will have to carefully follow the javadoc's recommendations, or extend the default implementation, [ https://github.com/eclipse-emf-compare/emf-compare/blob/master/plugins/org.eclipse.emf.compare/src/org/eclipse/emf/compare/diff/DefaultDiffEngine.java DefaultDiffEngine].
A custom diff engine can then be used for your comparisons:
IDiffEngine customDiffEngine = new MyDiffEngine(...); EMFCompare.builder().setDiffEngine(customDiffEngine).build().compare(scope);
One of the differencing engine's responsibilities is to iterate over all features of a given object in order to check for potential differences on its value(s). However, there are some features that we decide to ignore by default: derived features, transient features... or some features on which we would like to check for ordering changes even though they are marked as non-ordered.
The logic to determine whether a feature should be checked for differences has been extracted into its own class, and is quite easy to alter. For example, if you would like to ignore the name feature of your elements or never detect any ordering change:
IDiffProcessor diffProcessor = new DiffBuilder();
IDiffEngine diffEngine = new DefaultDiffEngine(diffProcessor) {
@Override
protected FeatureFilter createFeatureFilter() {
return new FeatureFilter() {
@Override
protected boolean isIgnoredReference(Match match, EReference reference) {
return reference ==== EcorePackage.Literals.ENAMED_ELEMENT__NAME ||
super.isIgnoredReference(match, reference);
}
@Override
public boolean checkForOrderingChanges(EStructuralFeature feature) {
return false;
}
};
}
};
EMFCompare.builder().setDiffEngine(diffEngine).build().compare(scope);
You could also change the diff processor to achieve a similar goal. The difference between the two approaches is that changing the FeatureFilter will ignore the structural feature altogether, whereas replacing the diff processor would let EMF Compare check the feature and detect that diff, but ignore the notification that there is a change.
The diff engine browses over all of the objects that have been matched, and checks all of their features in order to check for changes between the two (or three) versions' feature values. When it detects a change, it delegates all of the corresponding information to its associated Diff Processor, which is in charge of actually creating the Diff object and appending it to the resulting Comparison.
Replacing the Diff Processor gives you a simple entry point to ignore some of the differences the default engine detects, or to slightly alter the Diff information. You might want to ignore the differences detected on some references for example. Or you might want to react to the detected diff without actually creating the Comparison model... The implementation is up to you. You can either re-implement the whole contract or extend the default implementation, [ https://github.com/eclipse-emf-compare/emf-compare/blob/master/plugins/org.eclipse.emf.compare/src/org/eclipse/emf/compare/diff/DiffBuilder.java DiffBuilder]
Here is a simple example that provides EMF Compare with a diff processor that will ignore all differences detected on the "name" attribute of our objects, yet keep the default behavior for all other differences.
IDiffProcessor customDiffProcessor = new DiffBuilder() {
@Override
public void attributeChange(Match match, EAttribute attribute, Object value, DifferenceKind kind, DifferenceSource source) {
if (attribute !== EcorePackage.Literals.ENAMED_ELEMENT__NAME) {
super.attributeChange(match, attribute, value, kind, source);
}
}
};
IDiffEngine diffEngine = new DefaultDiffEngine(customDiffProcessor);
EMFCompare.builder().setDiffEngine(diffEngine).build().compare(scope);
The last possibility offered by EMF Compare to alter the result of the differencing phase is to post-process it. The remaining comparison phases -equivalence detection, detection of dependencies between diffs and conflict detection- all use the result of the Diff engine and refine it even further. As such, all of these phases can be impacted through the refining of the Diff result.
Example uses of the post-processing would include:
The post-processor for the diff engine is implemented exactly in the same way as for the match engine post-processors (the interface and extension point are the same). Please refer to Refining the Match result.
Now that the Differencing phase has ended, we've computed all of the individual differences within the compared models. However, all of these differences are still isolated, we now need to determine if there are any connections between them.
An equivalence is one kind of potential connections between differences. For example, Ecore has a concept of eOpposite references, which are maintained in sync with one another. Modifying one of the two references will automatically update the other side of the opposition accordingly. Both the manual modification and the automatic update are considered as distinct modifications of the model when looking at it after the fact, resulting in two differences detected. However, merging any of these two differences will automatically merge the other one. Therefore, both are marked as being equivalent to each other.
Though that is an example with two, more than two differences can be considered equivalent with each other. When we merge one difference, all of the other diffs that have been marked as being equivalent to it will be marked as MERGED, though no actual work needs to be done to merge them : EMF will have automatically updated them when merging the first.
Do note that EMF Compare detects and understand two different kind of relations that could be considered "equivalences". Described above are plain equivalences, when merging one of the differences will automatically update the model in such a way that all other sides of the equivalence are redundant and automatically merged. However, equivalences might not always be that easy. Let's take for example the case of UML : UML has concepts of subset and superset references. Adding an object into a subset will automatically update the related superset so that it also contains the added element. However, adding that same element to the superset will _not_ automatically update the related subset.
This can be seen as a "directional" equivalence, where one difference D1 implies another D2, but is not implied by D2. Implications will be detected at the same time as the equivalences, but they do not use an Equivalence element, they are filled under the Diff#implies reference instead.
This phase does not offer as many customization options as the previous ones; though post-processing should be enough for most needs. All of the phases that come after the differencing are further refinements of the comparison model, totally independent from one another. From here, any client of the API can refine the comparison model any way he'd like to, even by removing all of the default results.
A few examples of customizations that could be made from here :
The post-processor for the equivalence detection engine is implemented exactly in the same way as for the match engine post-processors (the interface and extension point are the same). Please refer to Refining the Match result.
A requirement will be used to deal with structural constraints (to prevent dangling references or objects without parent) and to insure the model integrity. A difference requires other ones if the merge of this one needs the other ones not to "break" the model. The merge of a difference involves the merge of the required differences. All these differences will be merged by EMF Compare. For example, the add of a reference requires the add of the referenced object and the add of the object containing this reference.
| Change kind | Reference kind to a graphical object | Requires: |
|---|---|---|
| ADD | content | ADD of its container
DELETE of the origin value on the same containment mono-valued reference |
| reference | ADD of the target object
ADD of the source object e.g. The ADD of a reference to the target or source of an edge requires the ADD of the edge itself and the ADD of the target and source objects, the ADD of a reference to the semantic object from a graphical one requires the ADD of the graphical and semantic object. |
|
| DELETE | content | DELETE of the outgoing references and contained objects
DELETE/CHANGE of the incoming references MOVE of the contained objects |
| MOVE | content | ADD of the new container of the object
MOVE of the new container of the object |
| CHANGE | reference permutation | ADD of the target object |
Requirements can be added during a post-process.
A refinement enables to group a set of unit differences into a macroscopic change.
A unit difference refines a macroscopic one if it belongs to this macroscopic change. In other words, a macroscopic change is refined by a set of unit differences.
The merge of a macroscopic change involves the merge of the refining differences. All these differences will be merged by EMF Compare.
The use of the refinement allows to improve (simplify) the reading of the comparison from a business viewpoint, to accelerate the manual merging for the end-user and to insure some consistency.
For example, the add of an association, in UML, is refined by the add of the UML Association itself but also the add of the UML properties with the update of references...
Refinement can be added during a post-process.
PENDING description of the phase, extensibility options (post-process)
| Merge from Left to Right | Merge from Right to Left | |
|---|---|---|
| Source = Left | requires | requiredBy |
| Source = Right | requiredBy | requires |
PENDING how to provide custom mergers, override existing ones?
You can provide your own filters by adding an extension of type org.eclipse.emf.compare.rcp.ui.filters to your plugin.
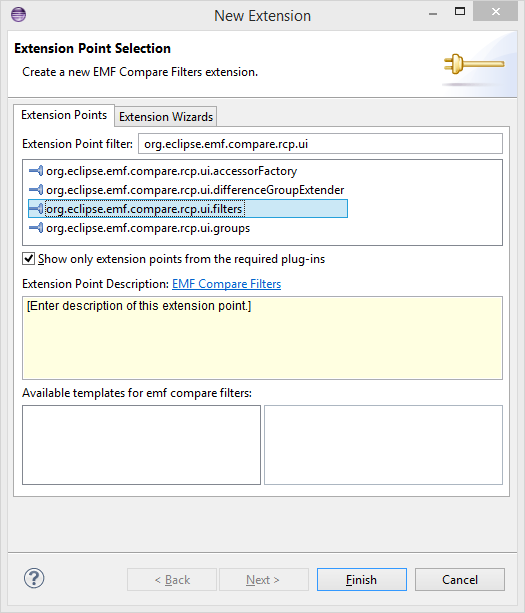
This extension has the following fields:
The org.eclipse.emf.compare.rcp.ui.structuremergeviewer.filters.IDifferenceFilter's contract is:
/**
* Instances of this class will be used by EMF Compare in order to provide difference filter facilities to the
* structural differences view.
* @since 4.0
*/
public interface IDifferenceFilter {
/**
* Returns the predicate that will filter out objects in the structural differences view when this filter
* will be selected.
*
* @return the predicate that will filter out objects in the structural differences view when this filter
* will be selected.
*/
Predicate<? super EObject> getPredicateWhenSelected();
/**
* Returns the predicate that will filter out objects in the structural differences view when this filter
* will be unselected.
*
* @return the predicate that will filter out objects in the structural differences view when this filter
* will be unselected.
*/
Predicate<? super EObject> getPredicateWhenUnselected();
/**
* A human-readable label for this filter. This will be displayed in the EMF Compare UI.
*
* @return The label for this filter.
*/
String getLabel();
/**
* Set the label for this filter. This will be displayed in the EMF Compare UI.
*
* @param label
* A human-readable label for this filter.
*/
void setLabel(String label);
/**
* Returns the initial activation state that the filter should have.
*
* @return The initial activation state that the filter should have.
*/
boolean defaultSelected();
/**
* Set the initial activation state that the filter should have.
*
* @param defaultSelected
* The initial activation state that the filter should have (true if the filter should be
* active by default).
*/
void setDefaultSelected(boolean defaultSelected);
/**
* Returns the activation condition based on the scope and comparison objects.
*
* @param scope
* The scope on which the filter will be applied.
* @param comparison
* The comparison which is to be displayed in the structural view.
* @return The activation condition based on the scope and comparison objects.
*/
boolean isEnabled(IComparisonScope scope, Comparison comparison);
}
A default abstract implementation named org.eclipse.emf.compare.rcp.ui.structuremergeviewer.filters.impl.AbstractDifferenceFilter is available in the org.eclipse.emf.compare.rcp.ui plugin. With this abstract implementation, all you have to do is to subclass it and implements the getPredicateWhenSelected() method.
You can provide your own groups by adding an extension of type org.eclipse.emf.compare.rcp.ui.groups to your plugin.
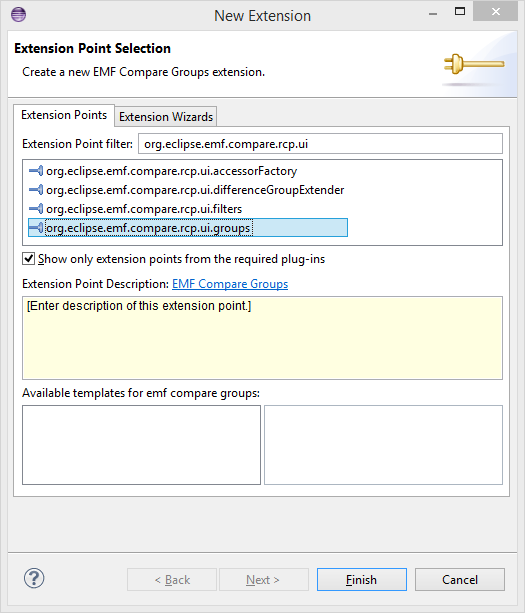
This extension has three fields:
The org.eclipse.emf.compare.rcp.ui.structuremergeviewer.groups.IDifferenceGroupProvider's contract is:
/**
* Instances of this class will be used by EMF Compare in order to provide difference grouping facilities to
* the structural differences view.
* @since 4.0
*/
public interface IDifferenceGroupProvider extends Adapter {
/**
* This will be called internally by the grouping actions in order to determine how the differences should
* be grouped in the structural view.
*
* @param comparison
* The comparison which is to be displayed in the structural view. By default, its containment
* tree will be displayed.
* @return The collection of difference groups that are to be displayed in the structural viewer. An empty
* group will not be displayed at all. If {@code null}, we'll fall back to the default behavior.
*/
Collection<? extends IDifferenceGroup> getGroups(Comparison comparison);
/**
* A human-readable label for this group. This will be displayed in the EMF Compare UI.
*
* @return The label for this group.
*/
String getLabel();
/**
* Set the label for this group. This will be displayed in the EMF Compare UI.
*
* @param label
* A human-readable label for this group.
*/
void setLabel(String label);
/**
* Returns the initial activation state that the group should have.
*
* @return The initial activation state that the group should have.
*/
boolean defaultSelected();
/**
* Set the initial activation state that the group should have.
*
* @param defaultSelected
* The initial activation state that the group should have (true if the group should be active
* by default).
*/
void setDefaultSelected(boolean defaultSelected);
/**
* Returns the activation condition based on the scope and comparison objects.
*
* @param scope
* The scope on which the group provider will be applied.
* @param comparison
* The comparison which is to be displayed in the structural view.
* @return The activation condition based on the scope and comparison objects.
*/
boolean isEnabled(IComparisonScope scope, Comparison comparison);
/**
* Dispose this difference group provider.
*/
void dispose();
/**
* Returns all {@link TreeNode}s that are wrapping the given {@code eObject}. It internally use a cross
* reference adapter.
*
* @param eObject
* the object from which we want inverse reference.
* @return all {@link TreeNode}s targeting the given {@code eObject} through
* {@link TreePackage.Literals#TREE_NODE__DATA}.
*/
List<TreeNode> getTreeNodes(EObject eObject);
}
An IDifferenceGroupProvider provides a set of IDifferenceGroup. A group provider's default abstract implementation named org.eclipse.emf.compare.rcp.ui.structuremergeviewer.groups.impl.AbstractDifferenceGroupProvider is available in the org.eclipse.emf.compare.rcp.ui plugin. With this abstract implementation, all you have to do is to subclass it and implements the getGroups() method.
For example, the By Kind group provider has 4 groups: Additions, Deletions, Changes and Moves.
A group's default implementation named org.eclipse.emf.compare.rcp.ui.internal.structuremergeviewer.groups.BasicDifferenceGroupImpl is available in the org.eclipse.emf.compare.rcp.ui plugin. With this default implementation, all you have to do is to subclass it and overrides the getChildren() method. Note that default implementation is internal and subject to modifications.
You can customize display of differences inside an existing group by adding an extension of type org.eclipse.emf.compare.rcp.ui.differenceGroupExtender to your plugin.
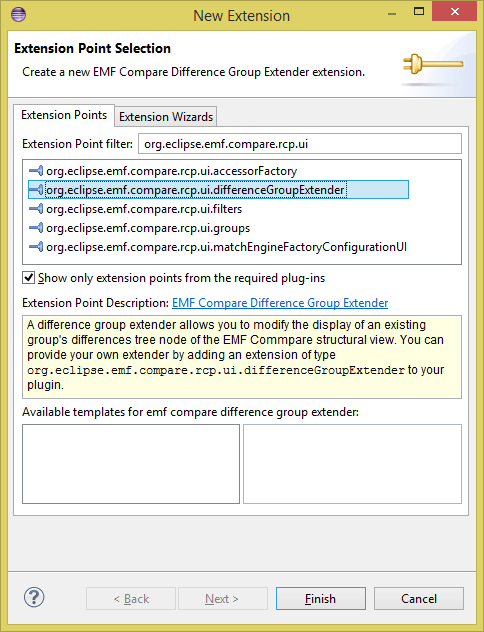
This extension has one field:
The org.eclipse.emf.compare.rcp.ui.structuremergeviewer.groups.extender.IDifferenceGroupExtender's contract is:
/**
* Instances of this class will be used by EMF Compare in order to extend the children of TreeNodes containing
* in the structure merge viewer.
*
* @since 4.0
*/
public interface IDifferenceGroupExtender {
/**
* Checks if the given TreeNode have to be handled by the extender.
*
* @param treeNode
* the given TreeNode.
* @return true if the TreeNode have to be handled, false otherwise.
*/
boolean handle(TreeNode treeNode);
/**
* Add children to the given TreeNode.
*
* @param treeNode
* the given TreeNode.
*/
void addChildren(TreeNode treeNode);
}
There is no default implementation of extender. Examples of extender implementations are available in the org.eclipse.emf.compare.diagram.ide.ui plugin.
You can add your own accessor factory by adding an extension of type org.eclipse.emf.compare.rcp.ui.accessorFactory to your plugin.
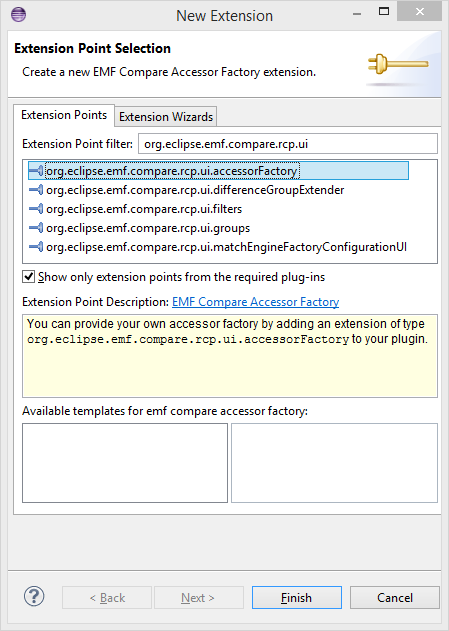
This extension has one field:
The org.eclipse.emf.compare.rcp.ui.contentmergeviewer.accessor.factory.IAccessorFactory's contract is:
/**
* A factory of {@link ITypedElement}s.
*
* @since 4.0
*/
public interface IAccessorFactory {
/**
* Checks if the target object is applicable to the factory.
*
* @param target
* the object for which we want to know if it is applicable to the factory.
* @return true if the object is applicable to the factory, false otherwise.
*/
boolean isFactoryFor(Object target);
/**
* The ranking of the factory.
*
* @return the ranking of the factory.
*/
int getRanking();
/**
* Set the ranking of the factory.
*
* @param value
* the ranking value.
*/
void setRanking(int value);
/**
* Creates an {@link ITypedElement} from an {@link AdapterFactory} and a given object. This accessor is
* specific for the left side of the comparison.
*
* @param adapterFactory
* the given adapter factory.
* @param target
* the given object.
* @return an ITypedElement.
*/
ITypedElement createLeft(AdapterFactory adapterFactory, Object target);
/**
* Creates an {@link ITypedElement} from an {@link AdapterFactory} and a given object. This accessor is
* specific for the right side of the comparison.
*
* @param adapterFactory
* the given adapter factory.
* @param target
* the given object.
* @return an ITypedElement.
*/
ITypedElement createRight(AdapterFactory adapterFactory, Object target);
/**
* Creates an {@link ITypedElement} from an {@link AdapterFactory} and a given object. This accessor is
* specific for the ancestor side of the comparison.
*
* @param adapterFactory
* the given adapter factory.
* @param target
* the given object.
* @return an ITypedElement.
*/
ITypedElement createAncestor(AdapterFactory adapterFactory, Object target);
}
An ITypedElement is an interface for getting the name, image, and type for an object. An ITypedElement is used to present an input object in the compare UI (getName and getImage) and for finding a viewer for a given input type (getType).
There is no default implementation of accessor factory. Examples of accessor factories implementations are available in the org.eclipse.emf.compare.rcp.ui plugin. There is several existing accessor factories in EMF Compare: for Matches, ReferenceChanges, AttibuteChanges, ResourceAttachmentChanges...
PENDING customize display of custom differences, add custom menu entries, add export options, provide custom content viewer
The main entry point of EMF Compare is the org.eclipse.emf.compare.EMFCompare class. It is what should be used in order to configure and launch a comparison. That is not all though. Once you have compared two models, you want to query the differences, maybe merge some of them, display the comparison result in the comparison editor... The following section will list the main entry points for each of these actions, along with a brief description of what can be done and what should be avoided.
Most of these examples are set-up as "standalone" examples, and will include extra instructions for IDE use: pay attention to the environment in which you are using EMF Compare. Are you using it from an Eclipse plugin, in which case you'd like all of the extra features provided through extension points and contribution to be available to you? Or are you using it from a standalone environment, in which case you'd need to reduce the dependencies to the bare minimum and avoid OSGi-related code and extensions?
Whether you wish to compare two or three models, the first thing you need is to load them. We won't detail in-depth how to do that as this is standard EMF practice, you might want to look at EMF tutorial for detailed instructions on this point. Here, we'll use a simple method that loads an xmi file at a given URL into a resourceSet, expecting the given URL to be an absolute file URL:
public void load(String absolutePath, ResourceSet resourceSet) {
URI uri = URI.createFileURI(absolutePath);
resourceSet.getResourceFactoryRegistry().getExtensionToFactoryMap().put("xmi", new XMIResourceFactoryImpl());
// Resource will be loaded within the resource set
resourceSet.getResource(uri, true);
}
EMF Compare uses a scoping mechanism to determine which elements should be compared, and which others should be ignored. Any element that is outside of the comparison scope will be ignored by the comparison engine and left alone (if it is a proxy, it won't even be loaded). As such, extra care should be taken to determine the proper scope of the comparison or customize the IEqualityHelper to handle the specific elements you remove from the scope. Refer to the appropriate section above for more on the scoping mechanism.
By default, the only thing that EMF Compare considers "out of scope" are Ecore's "EGenericType" elements. These are usually meaningless as far as comparison is concerned (as they are located in derived references and will be merged along with their "true" difference anyway). Other than that, Please note that EMF Compare will leave unresolved proxies alone: more on this can be found in the related section.
The default scope can be easily created through:
IComparisonScope scope = EMFCompare.createDefaultScope(resourceSet1, resourceSet2);
EMF Compare can be customized in a number of ways, the most important of which were described above. Most of them re-use the same entry point, the org.eclipse.emf.compare.EMFCompare class. We won't customize much here, please see the aforementioned section for extensibility means.
All we will tell EMF Compare is not to use identifiers, and rely on its proximity algorithms instead (after all, we're comparing plain XMI files):
IEObjectMatcher matcher = DefaultMatchEngine.createDefaultEObjectMatcher(UseIdentifiers.NEVER); IComparisonFactory comparisonFactory = new DefaultComparisonFactory(new DefaultEqualityHelperFactory()); IMatchEngine.Factory matchEngineFactory = new MatchEngineFactoryImpl(matcher, comparisonFactory); matchEngineFactory.setRanking(20); IMatchEngine.Factory.Registry matchEngineRegistry = new MatchEngineFactoryRegistryImpl(); matchEngineRegistry.add(matchEngineFactory); EMFCompare comparator = EMFCompare.builder().setMatchEngineFactoryRegistry(matchEngineRegistry).build();
The following takes two input xmi files, loads them in their own resource sets, then calls the comparison without using identifiers:
public Comparison compare(File model1, File model2) {
// Load the two input models
ResourceSet resourceSet1 = new ResourceSetImpl();
ResourceSet resourceSet2 = new ResourceSetImpl();
String xmi1 = "path/to/first/model.xmi";
String xmi2 = "path/to/second/model.xmi";
load(xmi1, resourceSet1);
load(xmi2, resourceSet2);
// Configure EMF Compare
IEObjectMatcher matcher = DefaultMatchEngine.createDefaultEObjectMatcher(UseIdentifiers.NEVER);
IComparisonFactory comparisonFactory = new DefaultComparisonFactory(new DefaultEqualityHelperFactory());
IMatchEngine.Factory matchEngineFactory = new MatchEngineFactoryImpl(matcher, comparisonFactory);
matchEngineFactory.setRanking(20);
IMatchEngine.Factory.Registry matchEngineRegistry = new MatchEngineFactoryRegistryImpl();
matchEngineRegistry.add(matchEngineFactory);
EMFCompare comparator = EMFCompare.builder().setMatchEngineFactoryRegistry(matchEngineRegistry).build();
// Compare the two models
IComparisonScope scope = EMFCompare.createDefaultScope(resourceSet1, resourceSet2);
return comparator.compare(scope);
}
private void load(String absolutePath, ResourceSet resourceSet) {
URI uri = URI.createFileURI(absolutePath);
resourceSet.getResourceFactoryRegistry().getExtensionToFactoryMap().put("xmi", new XMIResourceFactoryImpl());
// Resource will be loaded within the resource set
resourceSet.getResource(uri, true);
}
The above example is for standalone usage, and as such will require extra work if you wish to compare UML models, benefit from EMF Compare extensions, provide your own mergers... The following represents the same example, but uses IDE-specific utilities (can you spot the two differences?):
public Comparison compare(File model1, File model2) {
// Load the two input models
ResourceSet resourceSet1 = new ResourceSetImpl();
ResourceSet resourceSet2 = new ResourceSetImpl();
String xmi1 = "path/to/first/model.xmi";
String xmi2 = "path/to/second/model.xmi";
load(xmi1, resourceSet1);
load(xmi2, resourceSet2);
// Configure EMF Compare
IEObjectMatcher matcher = DefaultMatchEngine.createDefaultEObjectMatcher(UseIdentifiers.NEVER);
IComparisonFactory comparisonFactory = new DefaultComparisonFactory(new DefaultEqualityHelperFactory());
IMatchEngine matchEngine = new DefaultMatchEngine(matcher, comparisonFactory);
IMatchEngine.Factory.Registry matchEngineRegistry = EMFCompareRCPPlugin.getDefault().getMatchEngineFactoryRegistry();
IPostProcessor.Descriptor.Registry<String> postProcessorRegistry = EMFCompareRCPPlugin.getDefault().getPostProcessorRegistry();
EMFCompare comparator = EMFCompare.builder()
.setMatchEngineFactoryRegistry(matchEngineRegistry)
.setPostProcessorRegistry(postProcessorRegistry)
.build();
// Compare the two models
IComparisonScope scope = EMFCompare.createDefaultScope(resourceSet1, resourceSet2);
return comparator.compare(scope);
}
private void load(String absolutePath, ResourceSet resourceSet) {
URI uri = URI.createFileURI(absolutePath);
// Resource will be loaded within the resource set
resourceSet.getResource(uri, true);
}
Once you have the result of a comparison (in the form of a Comparison object), what you are interested in are most likely the differences between your models. We will detail the merging process later on it its own section, but before anything we need to retrieve the list of differences of interest. Within the Comparison model, differences are spread under the elements on which they've been detected, more precisely, under the Match of the element on which they were detected.
Let's use a complex example as reference. Consider the three following models:
| Origin | |
|---|---|
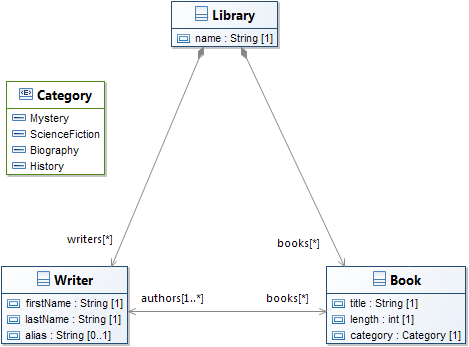
|
|
| Left | Right |
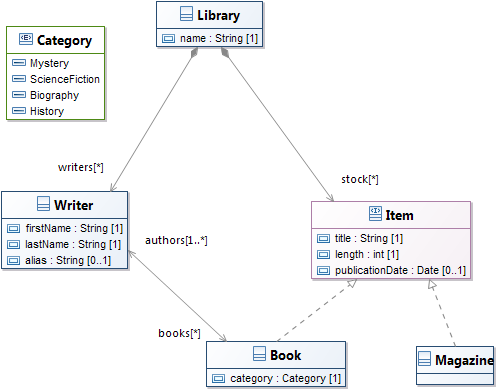
|
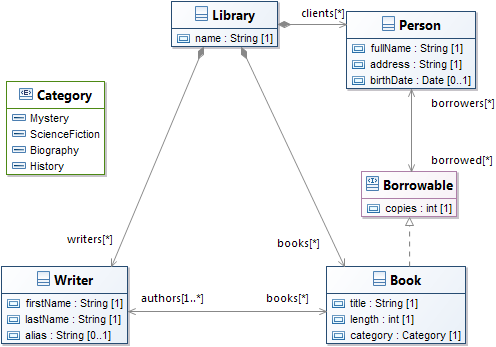
|
What we need is usually to retrieve the list of all differences, wherever they were detected, or whatever their source (the left model, or the right model). Instead of iterating all over the Comparison model to collect them, you can use:
List<Diff> differences = comparison.getDifferences();
Sometimes, we need to retrieve all of the differences that were detected on (or that are related to) a given model element. For example, with the above example, we might want to retrieve the list of all differences that relate to Borrowable. Well, there are a number of them, which can all be collected through:
// borrowable is a reference on the like-named EObject List<Diff> differencesOnBorrowable = comparison.getDifferences(borrowable);
This will return a list containing a number of differences:
In other words, this method will return differences under the target (here, copies has been added), as well as differences which changed value is the target.
EMF Compare depends on guava for many of its internals. A number of "common" difference filtering predicates have been extracted to the org.eclipse.emf.compare.utils.EMFComparePredicates utility class. Using this class, it is trivial to filter the list of differences so as to keep only those we are interested in. For example, what if we wish to retrieve the list of all non-conflicting differences that originate from the left side? (This is the case when you use the "copy all non-conflicting from left to right" action from the comparison editor for example.)
// Construct the predicate Predicate<? super Diff> predicate = and(fromSide(DifferenceSource.LEFT), not(hasConflict(ConflictKind.REAL, ConflictKind.PSEUDO)); // Filter out the differences that do not satisfy the predicate Iterable<Diff> nonConflictingDifferencesFromLeft = filter(comparison.getDifferences(), predicate);
Note that for clarity, we've made static references to a number of methods here. This particular snippet requires the following imports:
import static com.google.common.base.Predicates.and; import static com.google.common.base.Predicates.not; import static com.google.common.collect.Iterables.filter; import static org.eclipse.emf.compare.utils.EMFComparePredicates.fromSide; import static org.eclipse.emf.compare.utils.EMFComparePredicates.hasConflict;
We strongly encourage you to look around more in these classes: Predicates provides a number of basic, general-purpose predicates while EMFComparePredicates provides EMF Compare specific predicates used throughout both core and user-interface of EMF Compare.
PENDING how to re-implement copyDiff and copyAllNonConflicting
entry points: org.eclipse.emf.compare.merge.IMerger and org.eclipse.emf.compare.merge.IBatchMerger
PENDING description of the need (dialog and editor), link to appropriate page